正则表达式是描述字符模式的对象,在javascript中由RegExp(RegularExpression)类表示,String和RegExp都定义了支持正则地方法,且基本语法来自Perl5
导航
名词解释-->正则语法-->支持正则的对象-->demo-->瞎BB
名词解释
直接量字符:常量字符,单个字符,其length==1,即一个UTF-16编码
字符类:可以代表一串字符
量词:代表前方字符出现的次数
选择与分组:过滤-->将匹配到的对象当作主体,在主体中"再次"获取所需要的数据
描字符:定位,对位置的表示
修饰符:高级匹配规则
JavaScript中的正则定义/语法
直接常量符
javascript采用UTF-16编码的Unicode字符集,对于一些特殊字符,既可以直接使用其编码也可以使用转义符,简单地说直接常量符就是javascript的字符,与正则里直接使用,完全没区别(除了1.\cX,反正不会用,2.字符里的\”和\',在正则里直接使用"',反正不会错,3.退格符常量是[\b])
| 字符 | 助记 | 含义 |
|---|---|---|
| 字母和数字 | 自身 | |
| \o | Null->0->o | NUL字符(\u0000) |
| \t | Horizontal Tab (水平制表) | 制表符(\u0009) |
| \n | New Line(原本是Line Feed 馈行,缩写是LF) | 换行符(\u000A) |
| \v | Vertical Tab (垂直制表) | 垂直换行符(\u000B) |
| \f | Form Feed (馈页) | 换页符(\u000C) |
| \r | Carriage Return (回车) | 回车符(\u000D) |
| \xnn | 0x十六进制,单字符集(Latin1或者ISO-8859-1) | 由十六进制数nn指定的拉丁字符,简单地说就是ASCII,如\x0A->\n |
| \uxxxx | Unicode | 由十六进制数xxxx指定的Unicode字符 |
| \cX | Control(控制) | 包括\u0000-\u001f与\u007f在内的33个表示控制功能的字符,\cX只能在正则中使用 |
字符类
将直接常量放入括号内就组成了字符集合+使用助记符表示的常用字符集合,尽管称之为集合,实际上其只用来描述(代表)一个字符,很悲剧的看到助记符仅跟ASCII码有关
| 字符 | 助记 | 含义 |
|---|---|---|
| [……] | 方块内的任意字符 | |
| [^……] | 不在方块内的任意字符 | |
| . | 终止符以外的任意字符 | |
| \w | word | 任意ASCII组成的单词->[a-zA-Z0-9] |
| \W | 非word | 非任意非ASCII组成的单词->[^a-zA-Z0-9] |
| \s | space | 任意Unicode空白符 |
| \S | 非space | 任意非Unicode空白符 |
| \d | digit | 任意ASCII组成的数字->[0-9] |
| \D | 非digit | 任意非ASCII组成的数字->[^0-9] |
| [\b] | 退格符直接量,使用[],将特殊意义的\b转换为 |
常量
指定字符充分的标记,尽管称之为重复,其代表的只是匹配前一项的重复,而不是匹配到的字符的重复(即语法的常量,而非实例的常量,小绕口)
| 字符 | 含义 |
|---|---|
| {n,m} | 匹配前一项至少n次,但不超过m次 |
| {n,} | 匹配前一项至少n次 |
| {n} | 匹配前一项n次 |
| ? | 可选-->{0,1} |
| + | 至少/存在-->{1,} |
| * | 任意次数->{0,} |
选择,分组,引用
()拥有2中意义
1.分组操作,也是一般数学公式中的分组
2.匹配子项:将正则匹配到的主体称为母体,将左边第一个小括号内的数据称为第一子项,依次类推
| 字符 | 含义 |
|---|---|
| | | 选择,匹配该字符左侧或右侧的表达式,即语法中的或 |
| (...) | 组合+记忆(子项匹配),将匹配到的字符看做母体,在母体中继续进行匹配,非常方便 |
| (?:) | 只组合 |
| \n | 子项引用,n为数字,即对匹配到的字符进行使用 |
描字符
| 字符 | 含义 |
|---|---|
| ^ | 匹配前一项至少n次,但不超过m次 |
| $ | 匹配前一项至少n次 |
| \b | 匹配一个单词的边界,就是位于\w和\W之间的位置或\w与开头或结尾之间的位置 |
| \B | 非\b |
| (?=p) | 零宽正向先行断言,接下来的字符与p相同,但主体不包含p |
| (?!p) | 零宽负向先行断言,接下来的字符与p不相同,但主体不包含p |
修饰符
| 字符 | 含义 |
|---|---|
| i | 执行不区分大小写的匹配 |
| g | 执行全局匹配 |
| m | 多行匹配模式.将\n或\r看做开头或结尾,在语法中结合^或$使用 |
支持正则的对象
String 对象常用的四个方法,可以完成大多数情况下的正则需求
| 方法 | 描述 |
|---|---|
| match(searchvalue,regexp) | 找到一个或多个正则表达式的匹配。 |
| replace(regexp/substr,replacement) | 替换与正则表达式匹配的子串。(replacement可以是方法,故replace是循环遍历字符串的一种方式) |
| search(regexp) | 检索与正则表达式相匹配的值。 |
| split(separator,howmany) | 把字符串分割为字符串数组。 |
RegExp 对象
标准的正则表达式对象,比较常用2个方法,大概只会在需要建立"动态"正则的时候才会创建(有这需要的时候,自然会想到)
| 方法 | 描述 |
|---|---|
| exec(string) | 标准执行方法,包含分组对象(换句话说不支持全局模式) |
| test(string) | 检索字符串中指定的值。返回 true 或 false。 |
demo
这是jquery中的一些正则表达式,像core_rnotwhite,rtrim看看注释就能明白
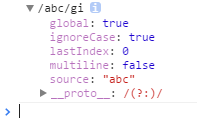
core_pnum:/[+-]?(?:\d*\.")\d+(?:[eE][+-]?\d+|)/.source注释写的很清楚,是用来表示任意数字的(包括正负,小数以及科学计数),source用来表示正则的语法内容(不带//),toString表示描述信息(正则标示符//内加上语法内容),这里看到source就应该清楚,下面绝逼是要使用RegExp创建正则去使用
第二部分有个(?:\d*\.")中的|,有量词+的意思,如果没有|,则整个数字不许包含小数点我们将(?:)全部去掉,并在我们分的四个部分上加入(),可以看到
除了第一个数组为我们需要的数组外,后面的就是所谓的分组,在做测试的时候也是超方便的存在,如果存在(?:)这种标志出现,基本可以确定在下面的使用中,移动会用到字数组(而且很可能每个都要用上,不用的都?:了)
rquickExpr:/^(?:(<[\w\W]+>)[^>]*"#([\w-]*))$/
判断是否为标签之间创建或为id查询的方式,可以看到这里的开头必须是<或者#,有时候对于$(" <div>")也是可以创建的,因为他们使用的正则是
rsingleTag: /^<(\w+)\s*\/?>(?:<\/\1>")$/
一个正确切严谨的标签的的收尾标签应该一致,所以使用了\1,代表匹配到的(\w+),可以发现诸如"<div /></div>"也是允许的
JsonExp
json正则的判断,小麻烦,略
瞎bb
描述字符模式的正则表达式作为一种比较规范的语法,学起来还算简单,只要了解了分组,基本上javascript上的正则就已经没什么难度了