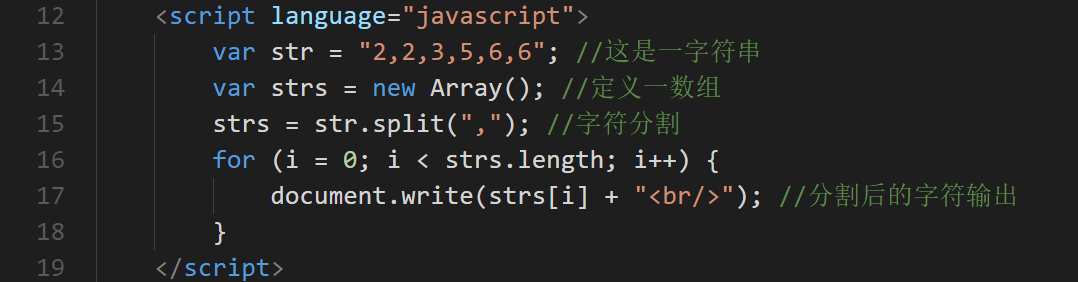
定义
JavaScript种正则表达式有两种定义方式,定义一个匹配类似 <%XXX%> 的字符串
1. 构造函数
var reg=new RegExp('<%[^%>]+%>','g');
2. 字面量
var reg=/<%[^%>]%>/g;
- g: global,全文搜索,默认搜索到第一个结果接停止
- i: ingore case,忽略大小写,默认大小写敏感
- m: multiple lines,多行搜索(更改^ 和$的含义,使它们分别在任意一行对待行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配)
元字符
正则表达式让人望而却步以一个重要原因就是其转义字符太多了,组合非常之多,但是正则表达式的元字符(在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符)并不多
元字符:( [ { \ ^ $ | ) ? * + .
并不是每个元字符都有其特定意义,在不同的组合中元字符有不同的意义,分类看一下
预定义特殊字符
| 字符 | 含义 |
| \t | 水平制表符 |
| \r | 回车符 |
| \n | 换行符 |
| \f | 换页符 |
| \cX | 与X对应的控制字符(Ctrl+X) |
| \v | 垂直制表符 |
| \0 | 空字符 |
字符类
一般情况下正则表达式一个字符(转义字符算一个)对应字符串一个字符,表达式 ab\t 的含义是
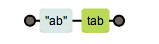
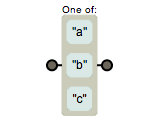
但是我们可以使用元字符[]来构建一个简单的类,所谓类是指,符合某些特征的对象,是一个泛指,而不是特指某个字符了,我们可以使用表达式 [abc] 把字符a或b或c归为一类,表达式可以匹配这类的字符
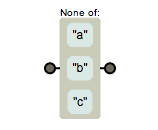
元字符[]组合可以创建一个类,我们还可以使用元字符^创建反向类/负向类,反向类的意思是不属于XXX类的内容,表达式 [^abc] 表示不是字符a或b或c的内容
范围类
按照上面的说明要是我们希望匹配单个数字那么表达式是这样的
[0123456789]
如果是字母那么。。。,好麻烦,正则表达式还提供了范围类,我们可以使用 x-y来连接两个字符表示从x到y的任意字符,这是个闭区间,也就是说包含x和ybenshen,这样匹配小写字母就很简单了
[a-z]
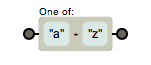
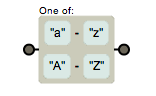
要是想匹配所有字母呢?在[]组成的类内部是可以连写的,我们还可以这样写 [a-zA-Z]
预定义类
刚才使用正则我们创建了几个类,来表示数字,字母等,但这样写也很是麻烦,正则表达式为我们提供了几个常用的预定义类来匹配常见的字符
| 字符 | 等价类 | 含义 |
| . | [^\n\r] | 除了回车符和换行符之外的所有字符 |
| \d | [0-9] | 数字字符 |
| \D | [^0-9] | 非数字字符 |
| \s | [ \t\n\x0B\f\r] | 空白符 |
| \S | [^ \t\n\x0B\f\r] | 非空白符 |
| \w | [a-zA-Z_0-9] | 单词字符(字母、数字、下划线) |
| \W | [^a-zA-Z_0-9] | 非单词字符 |
有了这些预定义类,写一些正则就很方便了,比如我们希望匹配一个 ab+数字+任意字符 的字符串,就可以这样写了 ab\d.

边界
正则表达式还提供了几个常用的边界匹配字符
|
字符 |
含义 |
|
^ |
以xx开头 |
|
$ |
以xx结尾 |
|
\b |
单词边界,指[a-zA-Z_0-9]之外的字符 |
|
\B |
非单词边界 |
看个不负责任的邮箱正则匹配(切勿模仿,小括号后面会讲到) \w+@\w+\.(com)$

量词
之前我们介绍的方法都是一一匹配的,如果我们希望匹配一个连续出现20次数字的字符串难道我们需要写成这样
\d\d\d\d...
为此正则表达式引入了一些量词
| 字符 | 含义 |
| ? | 出现零次或一次(最多出现一次) |
| + | 出现一次或多次(至少出现一次) |
| * | 出现零次或多次(任意次) |
| {n} | 出现n次 |
| {n,m} | 出现n到m次 |
| {n,} | 至少出现n次 |
看几个使用量词的例子
\w+\b Byron 匹配 单词+边界+Byron
(/\w+\b Byron/).test('Hi Byron'); //true
(/\w+\b Byron/).test('Welcome Byron'); //true
(/\w+\b Byron/).test('HiByron'); //false
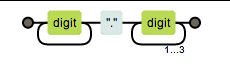
\d+\.\d{1,3} 匹配三位小数的数字
贪婪模式与非贪婪模式
看了上面介绍的量词,也许爱思考的同学会想到关于匹配原则的一些问题,比如{3,5}这个量词,要是在句子种出现了十次,那么他是每次匹配三个还是五个,反正3、4、5都满足3~5的条件,量词在默认下是尽可能多的匹配的,也就是大家常说的贪婪模式
'123456789'.match(/\d{3,5}/g); //["12345", "6789"]
既然有贪婪模式,那么肯定会有非贪婪模式,让正则表达式尽可能少的匹配,也就是说一旦成功匹配不不再继续尝试,做法很简单,在量词后加上 ? 即可
'123456789'.match(/\d{3,5}?/g); //["123", "456", "789"]
分组
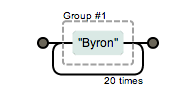
有时候我们希望使用量词的时候匹配多个字符,而不是像上面例子只是匹配一个,比如希望匹配Byron出现20次的字符串,我们如果写成 Byron{20} 的话匹配的是Byro+n出现20次,怎么把Byron作为一个整体呢?使用()就可以达到次目的,我们称为分组
(Byron){20}
如果希望匹配Byron或Casper出现20次该怎么办呢?可以使用字符 | 达到或的功效
(Byron|Casper){20}
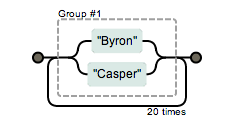
我们看到图中有个#1的东东,那是什么?使用分组的正则表达式会把匹配项也放到分组中,默认就是按数字编号分发的,各异根据编号获得捕获的分组内容,这个在一些希望具体操作第几个匹配项的函数中很有用
(Byron).(ok)
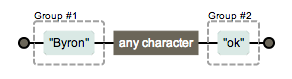
如果有分组嵌套的情况,外面的组的编号靠前
((^|%>)[^\t]*)
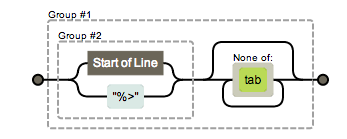
有时候我们不希望捕获某些分组,只需要在分组内加上 ?: 就可以了,着并不意味着该分组内容不属于正则表达式,只是不会给这个分组加编号了而已
(?:Byron).(ok)
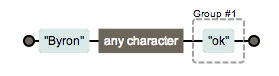
其实在C#等语言中分组还可以起名字,不过JavaScript不支持
前瞻
| 表达式 | 含义 |
| exp1(?=exp2) | 匹配后面是exp2的exp1 |
| exp1(?!exp2) | 匹配后面不是exp2的exp1 |
说的有些抽象,看个例子 good(?=Byron)
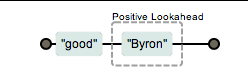
(/good(?=Byron)/).exec('goodByron123'); //['good']
(/good(?=Byron)/).exec('goodCasper123'); //null
(/bad(?=Byron)/).exec('goodCasper123');//null
通过上面例子可以看出 exp1(?=exp2) 表达式会匹配exp1表达式,但只有其后面内容是exp2的时候才会匹配,也就是两个条件,exp1(?!exp2) 比较类似
good(?!Byron)
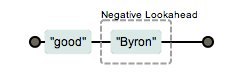
(/good(?!Byron)/).exec('goodByron123'); //null
(/good(?!Byron)/).exec('goodCasper123'); //['good']
(/bad(?!Byron)/).exec('goodCasper123');//null
参考
PS:博客中的图都是用第二个链接做的,帮助人图形化理解正则表达式,真心不错