如果您发现错误,请一定要告诉我,拯救一个辣鸡(但很帅)的少年就靠您了!
本文适合有 JavaScript 基础 && 面向搜索引擎书写正则的人群。
正则表达式是用于匹配字符串中字符组合的模式。正则表达式的模式规则是由一个字符序列组成的。包括所有字母和数字在内,大多数的字符都是直接按照直接量描述待匹配的字符。除此之外,正则表达式还有其他特殊语义的字符,这些字符不按照特殊含义进行匹配。
创建正则表达式
JavaScript 中的正则表达式用 RegExp 对象表示,有两种创建方式。
1. 直接量语法创建
正则表达式直接量定义为包含在一对斜杠(/)之间的字符。
2. 构造函创建
可以通过 RegExp() 构造函数可以实现动态创建正则表达式。RegExp 的第二个参数是可选的。
new RegExp(pattern [, flags])
RegExp(pattern [, flags])
其中 pattern 可以是字符串或者正则字面量。当 pattern 是字符串时,需要常规的字符转义规则,必须将 \ 替换成 \\,比如 /\w+/ 等价于 new RegExp("\\w+")。
直接量字符
正则表达式中所有字母和数字都是按照字面含义进行匹配的,其他非字母的字符需要通过反斜杠(\)作为前缀进行转移,如 \n 匹配换行符。这些字符为直接量字符(literal characters)。这些字符都是精确匹配,每一个字符都只能匹配一个字符。
在正则表达式中,有一些标点符号具有特殊含义,他们是:^ $ . * + ? = ! : | \ / ( ) [ ] { } 如果需要在正则表达式中与这些直接量进行匹配,必须使用前缀 \。
如果不记得哪些标点需要反斜杠转义,可以在每个标点符号前都加上反斜杠。
字符类
如果不想匹配某一个特定的字符而是想匹配某一类字符,则需要使用字符类。
通过将直接量字符放入方括号内,可以组成字符类(character class)。一个字符类可以匹配它所包含任意 一个 字符。如 [abc] 可以匹配 a,b,c 中任意一个字符。
使用 ^ 作为方括号中第一个字符来定义否定字符集,它匹配所有不包含在方框括号内的字符。[^] 可以匹配任意字符。
字符类可以使用连字符来表示字符范围。比如匹配小写字母[a-z],匹配任何字母和数字可以用[a-zA-Z0-9]。
一些常用的字符类,在 JavaScript 中有特殊的转义字符来表达它们。
| 字符 | 匹配 |
|---|---|
[...] |
方括号内任意字符 |
[^...] |
不在方括号内任意字符 |
. |
除了换行符和其他 Unicode 行终止符之外的任意字符 |
\w |
等价于 [a-zA-Z0-9_] |
\W |
等价于 [^a-zA-Z0-9_] |
\s |
任何 Unicode 空白符 |
\S |
任何非 Unicode 空白符的字符 |
\d |
等价于 [0-9] |
\D |
等价于 [^0-9] |
[\b] |
退格直接量,与退格键 \u0008 匹配,注意不同于 \b |
方括号内也可出现转义字符,如 [\d\s] 表示匹配任意空白符或数字。
但是 [.] 只能匹配 .。
重复
当一个模式需要被多次匹配的时候,正则表达式提供了表示重复的正则语法。
| 字符 | 含义 |
|---|---|
{n,m} |
匹配前一项至少 n 次,但不能超过 m 次 |
{n,} |
匹配前一项至少 n 次 |
{n} |
匹配前一项 n 次 |
? |
匹配前一项 0 次或 1 次,等价于 {0,1} |
+ |
匹配前一项 1 次或多次,等价于 {1,} |
* |
匹配前一项 0 次或多次,等价于 {0,} |
贪婪和非贪婪的重复
上面所有的重复都是“贪婪的”匹配,也就是匹配尽可能多的字符。如 /a+/ 匹配 'aaaa' 时,它会匹配 'aaaa' 。
如果想要尽可能少的匹配,只需要在重复的标记后加一个问号(?)即可。如 /a+?/ 匹配 'aaaa' 时,它会匹配 'a' 。
注意:正则表达式的模式匹配总会寻找字符串中第一个可能匹配的位置,这意味这 /a+?b/ 匹配 'aaab' 时,匹配到的是 'aaab' 而不是 'ab'。
选择、分组和引用
选择
字符 | 用于分隔供选择的模式,匹配时会尝试从左到右匹配每一个分组,直到发现匹配项。如 /ab|bc|cd/ 可以匹配字符串'ab'、'bc' 和 'cd'。
分组
圆括号可以把单独的项组合成子表达式,以便可以像一个独立的单元用 |、*、+ 或者 ? 对单元内的项进行处理。
引用
带圆括号的表达式的另一个用途是允许在同一个正则表达式的后面引用前面的子表达式。通过\后面加数字实现。\n 表示第 n 个带圆括号的子表达式。表示引用前一个表达式所匹配的文本。因为子表达式可以嵌套,所以根据子表达式左括号的位置进行计数。
例,能匹配 1999-01-01 或 1999/01/01 的正则:/\d{4}([-\/])\d{2}\1\d{2}/
具名引用
使用 (?<name>...) 的语法来为分组命名,并通过 \k<name> 在后面的正则表达式中引用。如上面的正则可以改写为:/\d{4}(?<separator>[-\/])\d{2}\k<separator>\d{2}/
忽略引用
如果只想用圆括号来表示子表达式,而不希望生成引用,可以使用 (?:) 来进行分组。例,/(?:a)(?:b)(c)/ 中 \1 将表示 (c) 所匹配的文本。
指定匹配位置(锚元素)
有一些正则表达式的元素不用来匹配实际的字符,而是匹配指定的位置。我们称这些元素为正则表达式的锚。
正则表达式中的锚字符包括:
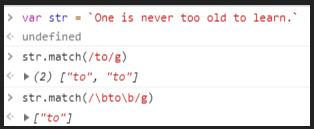
^用来匹配字符串的开始,多行检索时匹配一行的开头。$用来匹配字符串的结束,多行检索时匹配一行的结尾。\b用来匹配单词的边界,就是\w和\W之间的位置,或者\w和字符串的开头或结尾之间的位置。\B匹配非单词边界的位置。
例: /\bJava\b/ 可以匹配 Java 却不匹配 JavaScript。
任意正则表达式都可以作为锚点条件。
先行断言
(?=pattern) 它表示一个位置,该位置之后的字符能匹配 pattern 。如 /\d+(?=%)/ 匹配字符串 '100%' 中的 '100' 但是不匹配 '100。'
负向先行断言
(?!pattern) 它表示一个位置,该位置之后的字符能不匹配 pattern 。
后行断言
(?<=pattern) 它表示一个位置,该位置之前的字符能匹配 pattern 。例,/(?<=\$)\d+/ 匹配 '$100' 但是不匹配 '¥100'。
负向后行断言
(?<!pattern) 它表示一个位置,该位置之前的字符能不匹配 pattern。
修饰符
在正则表达式的第二条斜线之后,可以指定一个或多个修饰符,/pattern/g。
常用修饰符:
i执行不区分大小写的匹配。g全局匹配。m多行匹配模式。y“粘连”(sticky)修饰符。y修饰符的作用与g修饰符类似,也是全局匹配,后一次匹配都从上一次匹配成功的下一个位置开始。不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始,这也就是“粘连”的涵义。s表示点(.)可以表示任意字符,不设置的话,四个字节的 UTF-16 字符和行终止符不能用 . 表示。u开启 “Unicode 模式”,用来正确处理大于\uFFFF的 Unicode 字符。也就是说,会正确处理四个字节的 UTF-16 编码。
通过 RegExp.prototype.flags 可以获得正则修饰符的字符串。/pattern/ig.flags 返回 "gi"
字符串的正则方法
String.prototype.search(regexp|substr)
返回第一个和参数匹配的子串的起始位置。没有匹配子串返回 -1 。
如果参数不是正则表达式,将会通过 RegExp 构造函数转换成正则表达式。它会忽略正则的修饰符 g。
String.prototype.replace(regexp|substr, newSubStr|function)
第一个参数同search,查找指定子串。如果第二个表达式是字符串,将把第一个参数匹配的子串替换为 newSubStr。如果在替换字符串中出现了 $ 加数字,replace 将用与指定的子表达式相匹配的文本来替换这些字符。
例,单书名号包裹文本改为书名号。'<JavaScript>和<正则表达式>'.replace(/<([^_]*?)>/g, '《$1》') 会得到 "《JavaScript》和《正则表达式》"
使用字符串作为参数时替换字符串可以插入下面的特殊变量名:
?插入一个"$"$&插入匹配的子串。$`插入当前匹配的子串左边的内容。$'插入当前匹配的子串右边的内容。$n假如第一个参数是 RegExp对象,并且 n 是个小于100的非负整数,那么插入第 n 个括号匹配的字符串。提示:索引是从1开始
使用函数作为第二个参数
function replacer(match, p1, p2, p3, offset, string) { }
// match 匹配的子串。
// p1,p2, ... 假如replace()方法的第一个参数是一个RegExp 对象,则代表第n个括号匹配的字符串。
// offset 匹配到的子字符串在原字符串中的偏移量。子串首字母下标。
// string 被匹配的原字符串。
例,下划线命名转驼峰命名。'a_simple_name'.replace(/_([a-z])/g, (m, p1) => p1.toUpperCase()) 将得到 "aSimpleName"。
String.prototype.match(regexp)
参数 regexp 为一个正则表达式对象。如果传入一个非正则表达式对象,则会隐式地使用 new RegExp(obj) 将其转换为一个 RegExp 。
如果 regexp 没有设置修饰符 g,则仅返回第一个完整匹配及其相关的捕获组(Array),返回数组第一个字符是匹配字符串,余下的元素是正则表达式中圆括号括起来的子表达式。在这种情况下,返回的项目将具有如下所述的其他属性(groups: 一个捕获组数组 或 undefined(如果没有定义命名捕获组)。index: 匹配的结果的开始位置。input: 搜索的字符串。),或者未匹配时返回 null 。
如果使用 g 标志,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组,或者未匹配时返回 null 。
'196.168.0.1'.match(/(\d+)(?=.|$)/) // (?=.|$) 先行匹配 匹配 . 或者字符串结尾
// (2) ["196", "196", index: 0, input: "196.168.0.1", groups: undefined]
'196.168.0.1'.match(/(?<num>\d+)(?=.|$)/) // (?<name>) 具名引用 见上文
// (2) ["196", "196", index: 0, input: "196.168.0.1", groups: {num: "196"}]
'196.168.0.1'.match(/\d+(?=.|$)/g)
// (4) ["196", "168", "0", "1"]
String.prototype.split([separator[, limit]])
separator 指定表示每个拆分应发生的点的字符串,可以是一个字符串或正则表达式。如果空字符串("")被用作分隔符,则字符串会在每个字符之间分割。
limit 一个整数,限定返回的分割片段数量。
例,'张三;李四,王五|赵六'.split(/[;\|,]/) // (4) ["张三", "李四", "王五", "赵六"]
RegExp 的属性
flags会返回正则表达式的修饰符。- 表示对应修饰符是否存在的只读布尔值,
global(表示是否带有修饰符g),ignoreCase(i),multiline(m),sticky(y),dotAll(s),unicode(u) source只读字符串,包含正则表达式的文本。lastIndex可读/写整数。如果带有g修饰符,这个属性存储在整个字符串中下一次检索的开始位置。这个属性会被exec()和test()方法用到。
RegExp 的方法
exec()
如果没有找到任何属性,将返回 null,如果找到匹配返回一个数组,该数组第一个元素是相匹配的字符串,余下的元素是与圆括号内的子表达式相匹配的子串。
当调用 exec() 的正则表达式具有修饰符 g 时,它将把当前正则表达式对象的 lastIndex 属性设置为紧挨着匹配子串的字符位置。
注意即使两次匹配的不是同一个字符串,lastIndex 还是会连续生效的。
let reg = /\d+/g;
reg.exec('25*10=250'); // ["25", index: 0, input: "25*10=250", groups: undefined]
reg.lastIndex; // 2
reg.exec('666'); // ["6", index: 2, input: "666", groups: undefined]
reg.lastIndex; // 3
test()
调用 test() 和 exec() 等价,当 exec() 返回结果不是 null,test() 返回 true,否则返回 false 。
String 的方法不会用到 lastIndex 属性。