分布式 id 生成器
在分布式场景中,唯一 id 的生成算比较重要。
而通常在高并发场景中,需要类似 MySQL 自增 id 一样不断增长且又不会重复的 id,即 MySql 的主键 id。
比如,在电商 618 或者双 11 搞活动的时候,一般在 0 点 开始,会有千万到亿级的订单量写入,每秒大概需要处理 10 万加的订单。
而在将订单插入数据库之前,我们在业务上需要给订单一个唯一的 id,即利用 idMaker 生存唯一的订单号,再插入数据库内。如果生成的 id 是随机且没有含义的纯数字的话,在大订单量的情况下,对数据库进行增删改查时就不能起到提高效率的作用。所以 此 id 应该应该包含一些时间信息,机器信息等,这样即使后端的系统对消息进行了分库分表,也能够以时间顺序对这些消息进行排序了。
比较典型的就是推特的【雪花算法】了,在以上场景下可以算是最优解,原理如图:
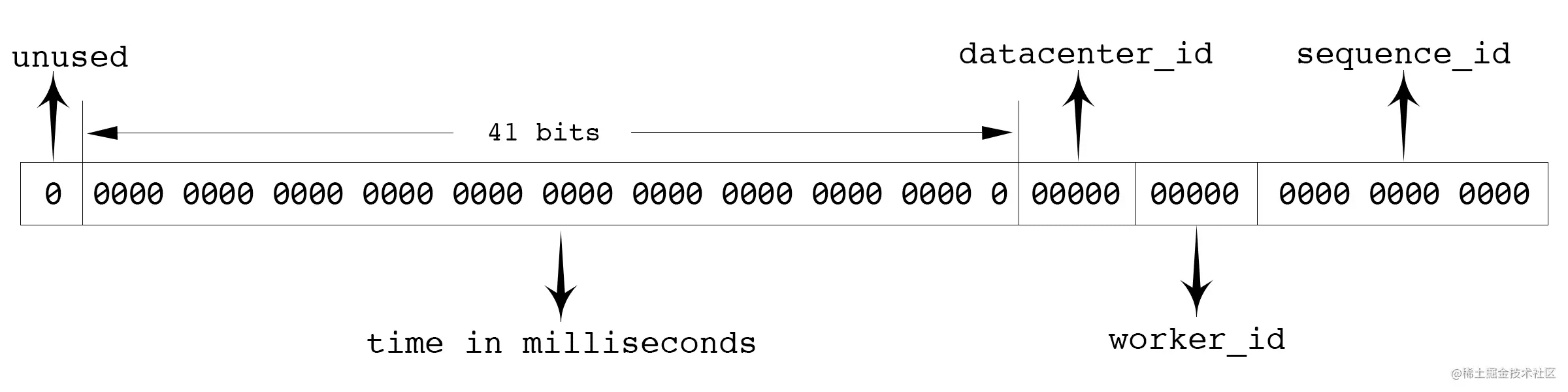
首先确定的是,id 数值长度是 64 位,int64 类型,除去开头的符号位 unused ,其它可以分为四个部分:
- 41 位来表示收到请求时的时间戳,单位为毫秒
- 5 位表示数据中心的 id
- 5 位表求机器的实例 id
- 12 位为循环自增 id,到达 1111,1111,1111 后归就会 0
以上机制原理生成的 id,可以支持一台机器在一毫秒内能够产生 4096 条消息。也就是一秒共 409.6w 条消息。单单从值域上来讲是完全够用。
数据中心 id 加上实例 id 共有 10 位,每个数据中心可以部署 32 台实例,搭建 32 个数据中心,所以可以一共部署 1024 台实例。
而 41 位的时间戳(毫秒为单位)能够使用 69 年。
worker_id 如何分配
timestamp(时间戳),datacenter_id(数据中心),worker_id(机器 ID) 和 sequence_id(序号) 这四个字段中,timestamp 和 sequence_id 是由程序在运行期生成的。但 datacenter_id 和 worker_id 需要在部署阶段就要能够获取得到,并且一旦程序启动之后,就是不可更改的了,因为如果可以随意更改,可能会造成最终生成的 id 有冲突。
不过一般不同数据中心的机器,会提供对应的获取数据中心 id 的 API,因此 datacenter_id 我们可以在部署阶段轻松地获取到。而 worker_id 是我们逻辑上给机器分配的一个 id,比较简单的做法就是由能够提供这种自增 id 功能的工具来支持,比如 MySql:
mysql> insert into a (ip) values("10.115.4.66");
Query OK, 1 row affected (0.00 sec)
mysql> select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 2 |
+------------------+
1 row in set (0.00 sec)
从 MySql 中获取到 worker_id 之后,就把这个 worker_id 直接持久化到本地,以避免每次上线时都需要获取新的 worker_id。让单实例的 worker_id 可以始终保持不变。
但是,使用 MySQL 的话,相当于给 id 生成服务增加了一个外部依赖。当然依赖越多,服务的运维成本就会增加。
考虑到集群中即使有单个 id 生成服务的实例挂了,也就是损失一段时间的一部分 id,所以我们也可以更简单暴力一些,把 worker_id 直接写在 worker 的配置中,上线时,由部署脚本完成 worker_id 字段替换即可。
开源示例:标准雪花算法
github.com/bwmarrin/snowflake 是一个相对轻量级的 snowflake 的 Go 实现。其文档对各位使用的定义如下图所示:

此库和标准的 snowflake 实现方式全完一致,使用也比较简单,直接上示例代码:
package main
import (
"fmt"
"github.com/bwmarrin/snowflake"
)
func main() {
node, err := snowflake.NewNode(1)
if err != nil {
println(err.Error())
os.Exit(1)
}
for i := 0; i < 20; i++ {
id := node.Generate()
fmt.Printf("Int64 ID: %d\n", id)
fmt.Printf("String ID: %s\n", id)
fmt.Printf("ID Time : %d\n", id.Time())
fmt.Printf("ID Node : %d\n", id.Node())
fmt.Printf("ID Step : %d\n", id.Step())
fmt.Println("--------- end ----------")
}
}
分布式锁
单机程序并发或并行修改全局共享变量时,需要对修改行为加锁。因为如果不加锁,多个协程序就会对该变量竞争,然后得到的结果就会不准确,或者说得到的结果不是我们所预期的,比如下面的例子:
package main
func main() {
var wg sync.WaitGroup
var count = 0
for i := 1; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
count++
}()
}
wg.Wait()
fmt.Println(count)
}
多次运行结果不同:
➜ go run main.go
884
➜ go run main.go
957
➜ go run main.go
923
预期的结果是:999
进程内加锁
而如果想要得到正确(预期)的结果,要把计数器的操作代码部分加上锁:
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
var lock sync.Mutex
var count = 0
for i := 1; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
lock.Lock() // 加锁
count++
lock.Unlock() // 释放锁
}()
}
wg.Wait()
fmt.Println(count)
}
这样能够得到正确结果:
➜ go run main.go
999
尝试加锁 tryLock
在某些场景,我们往往只希望一个任务有单一的执行者,而不像计数器一样,所有的 Goroutine 都成功执行。后续的 Goroutine 在抢锁失败后,需要放弃执行,这时候就需要用到尝试加锁,即实现 trylock。
尝试加锁,在加锁成功后执行后续流程,失败时不可以阻塞,而是直接返回加锁的结果。
在 Go 语言中可以用大小为 1 的 Channel 来模拟 trylock:
package main
import (
"fmt"
"sync"
)
type MyLock struct {
lockCh chan struct{}
}
func NewLock() MyLock {
var myLock MyLock
myLock = MyLock{
lockCh:make(chan struct{}, 1),
}
myLock.lockCh <- struct{}{}
return myLock
}
func (l *MyLock) Lock() bool {
result := false
select {
case <-l.lockCh:
result = true
default: // 这里去掉就会阻塞,直到获取到锁
}
return result
}
func (l *MyLock) Unlock() {
l.lockCh <- struct{}{}
}
func main() {
var wg sync.WaitGroup
var count int
l := NewLock()
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
if !l.Lock() {
fmt.Println("get lock failed")
return
}
count++
fmt.Println("count=", count)
l.Unlock()
}()
}
wg.Wait()
}
每个 Goruntine 只有获取到锁(成功执行了 Lock)才会继续执行后续代码,然后在 Unlock()时可以保证 Lock 结构体里的 Channel 一定是空的,所以不会阻塞也不会失败。
在单机系统中,tryLock 并不是一个好选择,因为大量的 Goruntine 抢锁会无意义地占用 cpu 资源,这就是活锁,所有不建议使用这种锁。
基于 Redis 的 setnx 分布式锁
在分布式场景中,也需要“抢占”的逻辑,可以用 Redis 的 setnx 实现:
package main
import (
"github.com/go-redis/redis"
"sync"
"time"
)
func setnx() {
client := redis.NewClient(&redis.Options{})
var lockKey = "counter_lock"
var counterKey = "counter"
// lock
resp := client.SetNX(lockKey, 1, time.Second*6)
lockStatus, err := resp.Result()
if err != nil || !lockStatus {
println("lock failed")
return
}
// counter++
getResp := client.Get(counterKey)
cntValue, err := getResp.Int64()
if err == nil || err == redis.Nil {
cntValue++
resp := client.Set(counterKey, cntValue, 0)
_, err := resp.Result()
if err != nil {
println(err)
}
}
println("current counter is ", cntValue)
// unlock
delResp := client.Del(lockKey)
unlockStatus, err := delResp.Result()
if err == nil && unlockStatus > 0 {
println("unlock success")
} else {
println("unlock failed", err)
}
}
func main() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func() {
defer wg.Done()
setnx()
}()
}
wg.Wait()
}
运行结果:
➜ go run main.go
lock failed
lock failed
lock failed
lock failed
lock failed
current counter is 34
lock failed
unlock success
通过上面的代码和执行结果可以看到,远程调用 setnx 运行流程上和单机的 troLock 非常相似,如果获取锁失败,那么相关的任务逻辑就不会继续向后执行。
setnx 很适合高并发场景下用来争抢一些“唯一”的资源。比如,商城秒杀的商品,在某个时间点,多个买家会对其进行下单并发争抢。这种场景我们没有办法依赖具体的时间来判断先后,因为不同设备的时间不能保证使用的是统一的时间,也就不能保证时序。
所以,我们需要依赖于这些请求到达 redis 节点的顺序来做正确的抢锁操作。
如果用户的网络环境比较差,是有可能抢不到的。
基于 ZooKeeper 分布式锁
基于 ZooKeeper 的锁与基于 Redis 的锁有点类似,不同之处在于 Lock 成功之前会一直阻塞,这与单机场景中的 mutex.Lock 很相似。
package main
import (
"github.com/go-zookeeper/zk"
"time"
)
func main() {
c, _, err := zk.Connect([]string{"127.0.0.1"}, time.Second)
if err != nil {
panic(err)
}
l := zk.NewLock(c, "/lock", zk.WorldACL(zk.PermAll))
err = l.Lock()
if err != nil {
panic(err)
}
println("lock success, do your business logic")
time.Sleep(time.Second * 10) // 模拟业务处理
l.Unlock()
println("unlock success, finish business logic")
}
其原理也是基于临时 Sequence 节点和 watch API,例如我们这里使用的是 /lock 节点。
Lock 会在该节点下的节点列表中插入自己的值,只要节点下的子节点发生变化,就会通知所有 watch 该节点的程序。这时候程序会检查当前节点下最小的子节点的 id 是否与自己的一致。如果一致,说明加锁成功了。
这种分布式的阻塞锁比较适合分布式任务调度场景,但不适合高频次持锁时间短的抢锁场景。
一般基于强一致协议的锁适用于粗粒度的加锁操作。这里的粗粒度指锁占用时间较长。我们在使用时也应思考在自己的业务场景中使用是否合适。
总结
本期主要介绍了分布式 id 的使用场景、分布式 id 如何生成的,以及分布式锁和使用。
- 雪花算法介绍和实现
- 分布式锁介绍和相关实现
以上就是go语言分布式id生成器及分布式锁介绍的详细内容,更多关于go 分布式id生成器 锁的资料请关注好代码网其它相关文章!