前言
前面有篇文章我们学习了 Go 语言空结构体详解,最近又在看 unsafe包的知识,在查阅相关资料时不免会看到内存对齐相关的内容,虽然感觉这类知识比较底层,但是看到了却不深究和渣男有什么区别?虽然我不会,但我可以学,那么这篇文章,我们就一起来看下什么是内存对齐吧!
说明:本文中的测试示例,均是基于Go1.17 64位机器
基础知识
在Go语言中,我们可以通过 unsafe.Sizeof(x) 来确定一个变量占用的内存字节数(不包含 x 所指向的内容的大小)。
例如对于字符串数组,在64位机器上,unsafe.Sizeof() 返回的任意字符串数组大小为 24 字节,和其底层数据无关:
func main() {
s := []string{"1", "2", "3"}
s2 := []string{"1"}
fmt.Println(unsafe.Sizeof(s)) // 24
fmt.Println(unsafe.Sizeof(s2)) // 24
}
对于Go语言的内置类型,占用内存大小如下:
| 类型 | 字节数 |
|---|---|
| bool | 1个字节 |
| intN, uintN, floatN, complexN | N/8 个字节 (int32 是 4 个字节) |
| int, uint, uintptr | 计算机字长/8 (64位 是 8 个字节) |
| *T, map, func, chan | 计算机字长/8 (64位 是 8 个字节) |
| string (data、len) | 2 * 计算机字长/8 (64位 是 16 个字节) |
| interface (tab、data 或 _type、data) | 2 * 计算机字长/8 (64位 是 16 个字节) |
| []T (array、len、cap) | 3 * 计算机字长/8 (64位 是 24 个字节) |
func main() {
fmt.Println(unsafe.Sizeof(int(1))) // 8
fmt.Println(unsafe.Sizeof(uintptr(1))) // 8
fmt.Println(unsafe.Sizeof(map[string]string{})) // 8
fmt.Println(unsafe.Sizeof(string(""))) // 16
fmt.Println(unsafe.Sizeof([]string{})) // 24
var a interface{}
fmt.Println(unsafe.Sizeof(a)) // 16
}
看个问题
基于上面的理解,那么对于一个结构体来说,占用内存大小就应该等于多个基础类型占用内存大小的和,我们就结合几个示例来看下:
type Example struct {
a bool // 1个字节
b int // 8个字节
c string // 16个字节
}
func main() {
fmt.Println(unsafe.Sizeof(Example{})) // 32
}
Example 结构体的三个基础类型,加起来一个 25字节,但是最终输出的却是 32字节。
我们再看两个结构体,即使这两个结构体包含的字段类型一致,但是顺序不一致,最终输出的大小也不一样:
type A struct {
a int32
b int64
c int32
}
type B struct {
a int32
b int32
c int64
}
func main() {
fmt.Println(unsafe.Sizeof(A{})) // 24
fmt.Println(unsafe.Sizeof(B{})) // 16
}
是什么导致了上述问题的呢,这就引出了我们要看的知识点:内存对齐。
什么是内存对齐
我们知道,在计算机中访问一个变量,需要访问它的内存地址,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是:在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置有限制,各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
内存对齐是编译器的管辖范围。表现为:编译器为程序中的每个“数据单元”安排在适当的位置上。
为什么需要内存对齐
- 有些
CPU可以访问任意地址上的任意数据,而有些CPU只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性,如果在编译时,将分配的内存进行对齐,这就具有平台可以移植性了。 CPU访问内存时并不是逐个字节访问,而是以字长(word size)为单位访问,例如 32位的CPU 字长是4字节,64位的是8字节。如果变量的地址没有对齐,可能需要多次访问才能完整读取到变量内容,而对齐后可能就只需要一次内存访问,因此内存对齐可以减少CPU访问内存的次数,加大CPU访问内存的吞吐量。
假设每次访问的步长为4个字节,如果未经过内存对齐,获取b的数据需要进行两次内存访问,最后再进行数据整理得到b的完整数据:
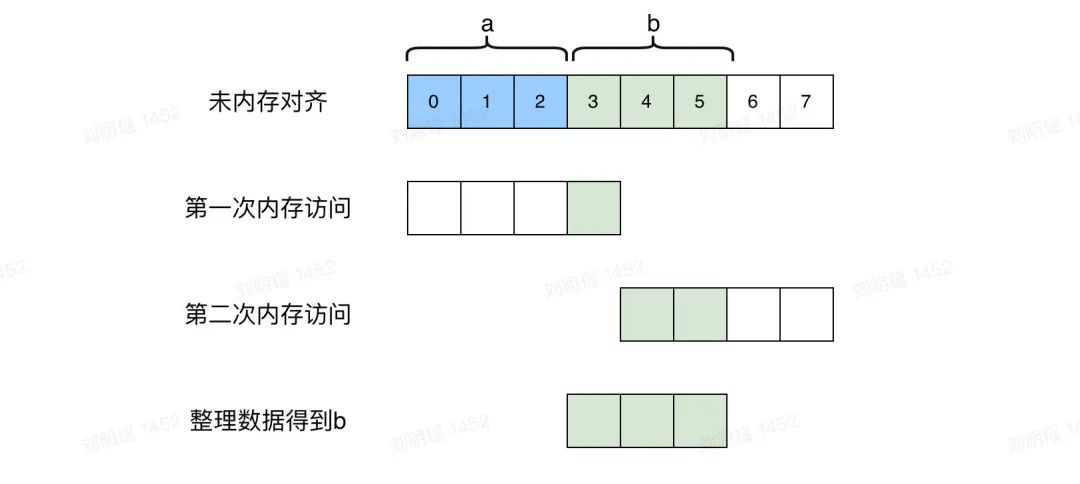
image-20220313230839425
如果经过内存对齐,一次内存访问就能得到b的完整数据,减少了一次内存访问:
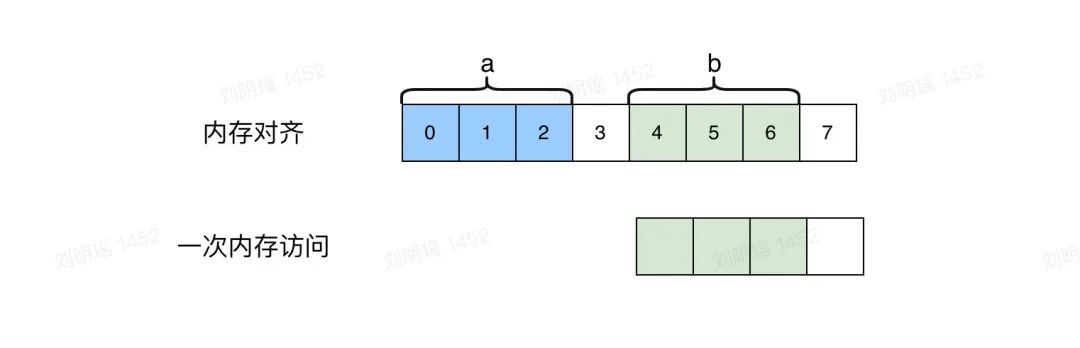
image-20220313231143302
unsafe.AlignOf()
unsafe.AlignOf(x) 方法的返回值是 m,当变量进行内存对齐时,需要保证分配到 x 的内存地址能够整除 m。因此可以通过这个方法,确定变量x 在内存对齐时的地址:
- 对于任意类型的变量 x ,
unsafe.Alignof(x)至少为 1。 - 对于 struct 结构体类型的变量 x,计算 x 每一个字段 f 的
unsafe.Alignof(x.f),unsafe.Alignof(x)等于其中的最大值。 - 对于 array 数组类型的变量 x,
unsafe.Alignof(x)等于构成数组的元素类型的对齐倍数。
对于系统内置基础类型变量 x ,unsafe.Alignof(x) 的返回值就是 min(字长/8,unsafe.Sizeof(x)),即计算机字长与类型占用内存的较小值:
func main() {
fmt.Println(unsafe.Alignof(int(1))) // 1 -- min(8,1)
fmt.Println(unsafe.Alignof(int32(1))) // 4 -- min (8,4)
fmt.Println(unsafe.Alignof(int64(1))) // 8 -- min (8,8)
fmt.Println(unsafe.Alignof(complex128(1))) // 8 -- min(8,16)
}
内存对齐规则
我们讲内存对齐,就是把变量放在特定的地址,那么如何计算特定地址呢,这就涉及到内存对齐规则:
成员对齐规则
针对一个基础类型变量,如果 unsafe.AlignOf() 返回的值是 m,那么该变量的地址需要 被m整除 (如果当前地址不能整除,填充空白字节,直至可以整除)。
整体对齐规则
针对一个结构体,如果 unsafe.AlignOf() 返回值是 m,需要保证该结构体整体内存占用是 m的整数倍,如果当前不是整数倍,需要在后面填充空白字节。
通过内存对齐后,就可以保证在访问一个变量地址时:
- 如果该变量占用内存小于字长:保证一次访问就能得到数据;
- 如果该变量占用内存大于字长:保证第一次内存访问的首地址,是该变量的首地址。
举个例子
例1:
type A struct {
a int32
b int64
c int32
}
func main() {
fmt.Println(unsafe.Sizeof(A{1, 1, 1})) // 24
}
1.第一个字段是 int32 类型,unsafe.Sizeof(int32(1))=4,内存占用为4个字节,同时unsafe.Alignof(int32(1)) = 4,内存对齐需保证变量首地址可以被4整除,我们假设地址从0开始,0可以被4整除:

成员变量1内存对齐
2.第二个字段是 int64 类型,unsafe.Sizeof(int64(1)) = 8,内存占用为 8 个字节,同时unsafe.Alignof(int64(1)) = 8,需保证变量放置首地址可以被8整除,当前地址为4,距离4最近的且可以被8整除的地址为8,因此需要添加四个空白字节,从8开始放置:

成员变量2内存对齐
3.第三个字段是 int32 类型,unsafe.Sizeof(int32(1))=4,内存占用为4个字节,同时unsafe.Alignof(int32(1)) = 4,内存对齐需保证变量首地址可以被4整除,当前地址为16,16可以被4整除:

成员变量3内存对齐
4.所有成员对齐都已经完成,现在我们需要看一下整体对齐规则:unsafe.Alignof(A{}) = 8,即三个变量成员的最大值,内存对齐需要保证该结构体的内存占用是 8 的整数倍,当前内存占用是 20个字节,因此需要再补充4个字节:

整体对齐
5.最终该结构体的内存占用为 24字节。
例二:
type B struct {
a int32
b int32
c int64
}
func main() {
fmt.Println(unsafe.Sizeof(B{1, 1, 1})) // 16
}
1.第一个字段是 int32 类型,unsafe.Sizeof(int32(1))=4,内存占用为4个字节,同时unsafe.Alignof(int32(1)) = 4,内存对齐需保证变量首地址可以被4整除,我们假设地址从0开始,0可以被4整除:

成员变量1内存对齐
2.第二个字段是 int32 类型,unsafe.Sizeof(int32(1))=4,内存占用为4个字节,同时unsafe.Alignof(int32(1)) = 4,内存对齐需保证变量首地址可以被4整除,当前地址为4,4可以被4整除:

成员变量2内存对齐
3.第三个字段是 int64 类型,unsafe.Sizeof(int64(1))=8,内存占用为8个字节,同时unsafe.Alignof(int64(1)) = 8,内存对齐需保证变量首地址可以被8整除,当前地址为8,8可以被8整除:

成员变量3内存对齐
4.所有成员对齐都已经完成,现在我们需要看一下整体对齐规则:unsafe.Alignof(B{}) = 8,即三个变量成员的最大值,内存对齐需要保证该结构体的内存占用是 8 的整数倍,当前内存占用是 16个字节,已经符合规则,最终该结构体的内存占用为 16个字节。
空结构体的对齐规则
如果空结构体作为结构体的内置字段:当变量位于结构体的前面和中间时,不会占用内存;当该变量位于结构体的末尾位置时,需要进行内存对齐,内存占用大小和前一个变量的大小保持一致。
type C struct {
a struct{}
b int64
c int64
}
type D struct {
a int64
b struct{}
c int64
}
type E struct {
a int64
b int64
c struct{}
}
type F struct {
a int32
b int32
c struct{}
}
func main() {
fmt.Println(unsafe.Sizeof(C{})) // 16
fmt.Println(unsafe.Sizeof(D{})) // 16
fmt.Println(unsafe.Sizeof(E{})) // 24
fmt.Println(unsafe.Sizeof(F{})) // 12
}
总结
本篇文章我们一起学习了Go 语言中的内存对齐,主要内容如下:
- unsafe.Sizeof(x) 返回了变量x的内存占用大小
- 两个结构体,即使包含变量类型的数量相同,但是位置不同,占用的内存大小也不同,由此引出了内存对齐
- 内存对齐包含成员对齐和整体对齐,与 unsafe.AlignOf(x) 息息相关
- 空结构体作为成员变量时,是否占用内存和所处位置有关
- 在实际开发中,我们可以通过调整变量位置,优化内存占用(一般按照变量内存大小顺序排列,整体占用内存更小)
以上就是详解Go语言中的内存对齐的详细内容,更多关于Go语言内存对齐的资料请关注好代码网其它相关文章!