前言:这篇文章主要是介绍如何使用采集功能去采集一个图片类的网站。这次选取的目标站点为:站酷网的佳作欣赏栏目,其URL为:http://www.zcool.com.cn/shows/。本文将会涉及到如何处理被采集页面含有分页以及如何使用简单的过滤规则。本文共分为三节:第一节,主要是介绍如何进入采集界面和新增采集节点中的第一步:设置基本信息及网址索引页规则;第二节,主要是介绍新增采集节点中的第二步:设置字段获取规则;第三节,主要是介绍如何采集指定节点和如何导出采集内容。
下面进入第一节。
1.1进入采集节点管理界面
如(图1)所示,在后台管理界面的主菜单中单击“采集”,然后单击“采集节点管理”,即可进入采集节点管理界面,如(图2)所示。
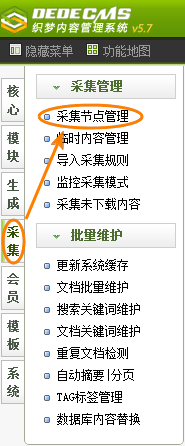
图1-后台管理界面

图2-采集节点管理界面
1.2. 增加新节点
在采集节点管理界面中,单击左下角的“增加新节点”或者右上角的“添加新节点”(如图2),都可进入“选择内容模型”界面,如(图3)所示,

图3-选择内容模型界面
在“选择内容模型”界面的下拉列表框中,有“普通文章”和“图片集”可供选择。
根据被采集页面的类型,选择相应的内容模型。本文这里选择“图片集”,单击确定后,便可进入“新增采集节点:第一步设置基本信息及网址索引页规则”界面,如(图4)所示,

图4-新增采集节点:第一步设置基本信息及网址索引页规则
1.2.1 设置节点基本信息
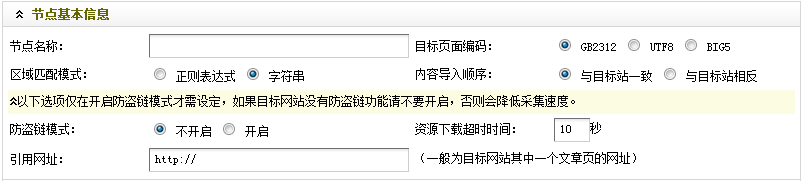
图5-节点基本信息
如(图5)所示,这里只是介绍如何获取“目标页面编码”,对于其他的设定,可参见之前的文章。具体操作步骤:
(a)打开被采集的目标页:http://www.zcool.com.cn/shows/;
(b)单击右键后选择“查看源文件”,找到“charset”, 如(图6)所示,

图6-查看源文件
其等号后面的代码就是所需填写的“编码格式”,这里是“utf-8”。
填写后,如(图7)所示,
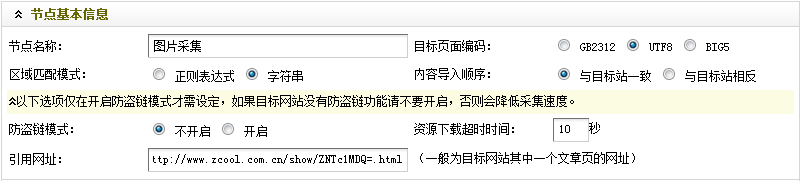
图7-设置后的节点基本信息
检查无误后,进入下一步设置。
1.2.2 设置列表网址获取规则
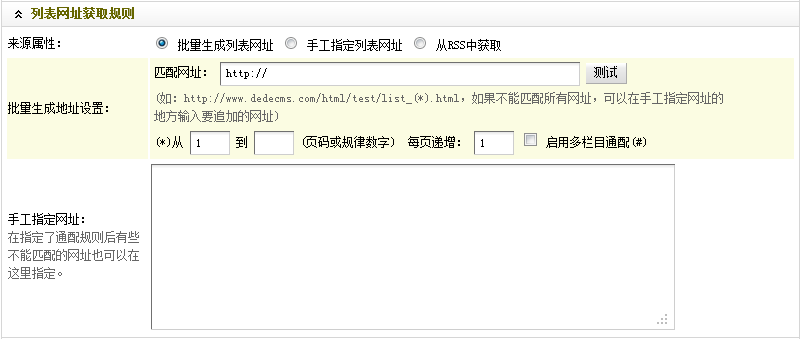
图8-列表网址获取规则
如(图8)所示,这里是设置被采集的文章列表页的匹配规则。具体操作步骤:
(a)首先,回到已打开的列表页,找到浏览器的URL地址栏中显示的网址和页面的换页部分。如(图9)和(图10)所示,

图9-浏览器的URL地址栏

图10-换页
(b)单击“2”,打开文章列表页的第二页,再次找到浏览器的URL地址栏中所显示的网址和页面的换页部分,如(图12)和(图13)所示,

图11-第二页的网址

图12-第二页的换页
(c)在已打开的列表页的第二页上面,单击(1),回到列表页的首页,这时页面的换页部分与之前的图10是相同的,然而浏览器的URL地址栏中所显示的网址与之前图9并不相同,如(图13)所示,

图13-第一页的网址
(d)由(b)和(c)可推知,这里被采集的列表页的网址所遵循规律为:
http://www.zcool.com.cn/shows/0!0!0!200!(*)!1!0!0/。稳妥起见,请自行测试更多列表页。确定规律后,在“匹配网址”中,填入列表页所遵循的规律。
(e)最后,根据需要指定采集的页码或者规律数字,并设定其递增规律。
到这里,“列表网址获取规则”部分就设置结束了。最后结果,如(图14)所示,
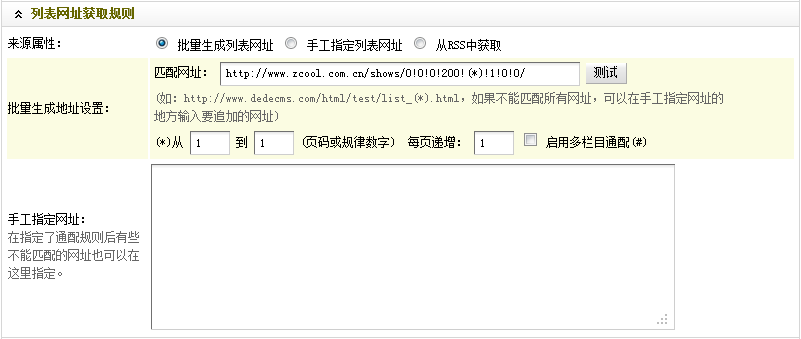
图14-设置后的列表网址获取规则
确定正确后,进入下一步设置。
1.2.3设置文章网址匹配规则
图15-文章网址匹配规则
这里是设置被采集的列表页的匹配规则。
具体操作步骤:
(a)对于“区域开始的HTML”,可以在已打开的列表首页,单击右键后选择“查看源文件”查找出第一篇文章的标题“高清壁纸”来获得,如(图16)所示,

图16-查看源文件中,第一篇文章的标题
通过观察,不难看出“<ul class="list_left_nr">”为整个列表的开始部分。因此,在“区域开始的HTML”中,应填入“<ul class="list_left_nr">”。
(b)在源文件中,找到最后一篇文章标题“阿奴比斯”,如(图17)所示,

图17-查看源文件中,最后一篇文章的标题
结合列表的开始部分并通过观察可知,第一个“</ul>”为整个列表的结束部分,而其后的从“<ul class=”list_left_bottomw”>”到第二个“</ul>”,则为页面的换页部分。因此,在“区域结束的HTML”中,应填入”</ul>”,意思是到第一个</ul>结束。
(c)经过观察图16和图17的文章标题部分,可以发现,标题的链接地址都是含有“=.html”的。因此,可在“必须包含”中,填入“=.html”。
到这里,“文章网址匹配规则“就设置结束了。填写后,如(图18)所示,
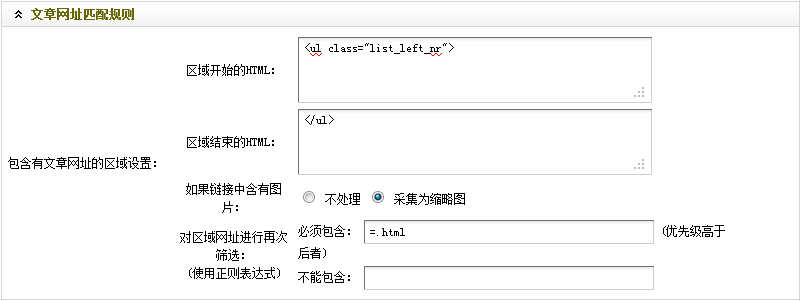
图18-设置后的文章网址匹配规则
通过以上的三个小节,新增采集节点的第一步就已经设置完成了。设置后的最终结果,如(图19)所示,
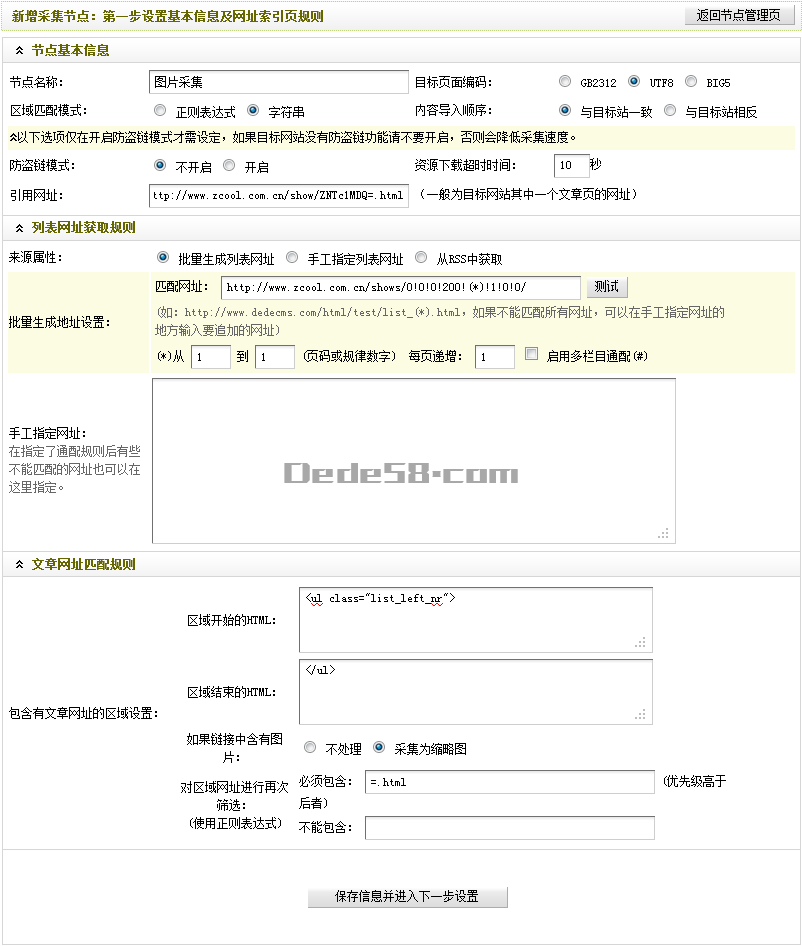
图19-设置后的新增采集节点:第一步设置基本信息及网址索引页规则
全部完成并检查无误后,单击“保存信息并进入下一步设置“。如果之前设置正确,单击后,将会进入“新增采集节点:测试基本信息及网址索引页规则设置的网址获取规则测试”页面并看到相应的文章列表地址。如(图20)所示,

图20-网址获取规则测试
确定正确无误后,单击“保存信息并进入下一步设置”。否则,请单击“返回上一步进行修改“。
到这里,第一节就结束了。下面进入第二节。。。
以上就是Dedecms织梦采集功能的如何使用方法好代码教程-图片集(一)。真正的坚韧,就应是哭的时候要彻底,笑的时候要开怀,说的时候要淋漓尽致,做的时候不好犹豫。更多关于Dedecms织梦采集功能的如何使用方法好代码教程-图片集(一)请关注haodaima.com其它相关文章!