SYN Flood攻击早在1996年就被发现,但至今仍然显示出强大的生命力。很多操作系统,甚至防火墙、路由器都无法有效地防御这种攻击,而且由于它可以方便地伪造源地址,追查起来非常困难。它的数据包特征通常是,源发送了大量的SYN包,并且缺少三次握手的最后一步握手ACK回复。
SYN Flood攻击原理
例如,攻击者首先伪造地址对服务器发起SYN请求(我可以建立连接吗?),服务器就会回应一个ACK+SYN(可以+请确认)。而真实的IP会认为,我没有发送请求,不作回应。服务器没有收到回应,会重试3-5次并且等待一个SYN Time(一般30秒-2分钟)后,丢弃这个连接。
如果攻击者大量发送这种伪造源地址的SYN请求,服务器端将会消耗非常多的资源来处理这种半连接,保存遍历会消耗非常多的CPU时间和内存,何况还要不断对这个列表中的IP进行SYN+ACK的重试。最后的结果是服务器无暇理睬正常的连接请求—拒绝服务。在服务器上用netstat –an命令查看SYN_RECV状态的话,就可以看到:
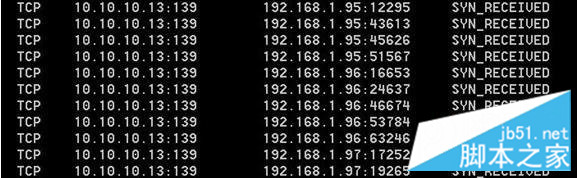
如果我们抓包来看:ACK回应情况

可以看到大量的SYN包没有ACK回应。
SYN Flood攻击防护
目前市面上有些防火墙具有SYN Proxy功能,这种方法一般是定每秒通过指定对象(目标地址和端口、仅目标地址或仅源地址)的SYN片段数的阀值,当来自相同源地址或发往相同目标地址的SYN片段数达到这些阀值之一时,防火墙就开始截取连接请求和代理回复SYN/ACK片段,并将不完全的连接请求存储到连接队列中直到连接完成或请求超时。当防火墙中代理连接的队列被填满时,防火墙拒绝来自相同安全区域(zone)中所有地址的新SYN片段,避免网络主机遭受不完整的三次握手的攻击。但是,这种方法在攻击流量较大的时候,连接出现较大的延迟,网络的负载较高,很多情况下反而成为整个网络的瓶颈;?
Random Drop:随机丢包的方式虽然可以减轻服务器的负载,但是正常连接的成功率也会降低很多;?
特征匹配:IPS上会常用的手段,在攻击发生的当时统计攻击报文的特征,定义特征库,例如过滤不带TCP Options 的syn 包等;
早期攻击工具(例如synkiller,xdos,hgod等)通常是发送64字节的TCP SYN报文,而主机操作系统在发起TCP连接请求时发送SYN 报文是大于64字节的。因此可以在关键节点上设置策略过滤64字节的TCP SYN报文,某些宣传具有防护SYN Flood攻击的产品就是这么做的。随着工具的改进,发出的TCP SYN 报文完全模拟常见的通用操作系统,并且IP头和TCP头的字段完全随机,这时就无法在设备上根据特定的规则来过滤攻击报文。这时就需要根据经验判断IP 包头里TTL值不合理的数据包并阻断,但这种手工的方法成本高、效率低。 图是某攻击工具属性设置。SYN Cookie攻击设置。

SYN Cookie:就是给每一个请求连接的IP地址分配一个Cookie,如果短时间内连续受到某个IP的重复SYN报文,就认定是受到了攻击,以后从这个IP地址来的包会被丢弃。但SYN Cookie依赖于对方使用真实的IP地址,如果攻击者利用SOCK_RAW随机改写IP报文中的源地址,这个方法就没效果了。
商业产品的防护算法
syn cookie/syn proxy类防护算法:这种算法对所有的syn包均主动回应,探测发起syn包的源IP地址是否真实存在;如果该IP地址真实存在,则该IP会回应防护设备的探测包,从而建立TCP连接;大多数的国内外抗拒绝服务产品采用此类算法。
safereset算法:此算法对所有的syn包均主动回应,探测包特意构造错误的字段,真实存在的IP地址会发送rst包给防护设备,然后发起第2次连接,从而建立TCP连接;部分国外产品采用了这样的防护算法。?
syn重传算法:该算法利用了TCP/IP协议的重传特性,来自某个源IP的第一个syn包到达时被直接丢弃并记录状态,在该源IP的第2个syn包到达时进行验证,然后放行。
综合防护算法:结合了以上算法的优点,并引入了IP信誉机制。当来自某个源IP的第一个syn包到达时,如果该IP的信誉值较高,则采用syncookie算法;而对于信誉值较低的源IP,则基于协议栈行为模式,如果syn包得到验证,则对该连接进入syncookie校验,一旦该IP的连接得到验证则提高其信誉值。有些设备还采用了表结构来存放协议栈行为模式特征值,大大减少了存储量。
以上就是SYN Flood攻击原理与防护的全部内容,希望对大家的学习有所帮助。